
Package Exports
- @digitak/bunker
This package does not declare an exports field, so the exports above have been automatically detected and optimized by JSPM instead. If any package subpath is missing, it is recommended to post an issue to the original package (@digitak/bunker) to support the "exports" field. If that is not possible, create a JSPM override to customize the exports field for this package.
Readme
Bunker
Bunker is a fast and compact JSON alternative to store and share data in a binary format with a friendly API.
It can be compared to MessagePack or Protocol Buffers.
Bunker is finely optimized to be very compact. In average, its output is 2.5x smaller than JSON and 2x smaller than MessagePack. See the data size comparison appendice for more details.
Bunker achieves this extreme density by:
- using a custom binary format for integers called elastic integers,
- working well with arrays of objects. Instead of writing repeatedly all objects with all keys like JSON and MessagePack do, it guesses the most accurate schema and write keys and types only once,
- memorizing and reusing strings and objects so that nothing is encoded twice.
Bunker is very compact but also extremely versatile as it can encode any data type.
Unlike JSON and MessagePack, Bunker correctly encode and decode:
- big integers,
- regular expressions,
- dates,
- arrays with properties,
- maps,
- sets,
- maps and sets with properties,
- instances of classes (you can store and retrieve your prototypes),
- and circular references.
This library is written in Typescript so you don't need to import types. It is compatible with Node, Deno and a browser environment (except for bunkerFile and debunkerFile that are only compatibles with Node).
Use cases
Bunker is great to:
- store data,
- share data between processes.
For example you can use Bunker to communicate between a server and a client with more efficiency and versatility than JSON.
You can also save your objects into bunker files and load them later on.
Or you can use Bunker to communicate between a process written in language X and another one written in language Y.
If you don't find a bunker library written in your favorite programming language, feel free to create your own by following the official bunker binary format specifications.
API
Bunker exports two main functions to encode and decode data:
bunkeris the equivalent ofJSON.stringify,debunkeris the equivalent ofJSON.parse.
function bunker(value: any, schema?: Schema): Uint8Array
function debunker(data: Uint8Array): unknownYou can encode and decode any value except functions.
If you store the resulting data in a file, it should have the
.bunkerextension.
bunker and debunker can be used in a browser, Node or Deno environment.
Basic example
import { bunker, debunker } from '@digitak/bunker'
const myObject = {
foo: 12,
bar: {
hello: "Hello",
you: "world"
}
}
const encoded = bunker(myObject)
const decoded = debunker(encoded)
console.log(decoded.foo) // print "12"Schema
When you encode data with bunker, the first step is to guess the schema of the object.
Guessing the most precise schema is the heaviest part of encoding data with Bunker. Manually indicating Bunker what schema to use will drastically improve encoding and decoding speed!
You can use a schema in two ways:
- on the fly by passing the schema to the
bunkerfunction, - or you can compile it to get an encoder and a decoder function.
For the exhaustive list of schema types exported by Bunker you can read the complete schema reference.
You can also browse examples of schemas written in Javascript.
On the fly schema
You pass the schema as a second argument to the bunker function.
Basic example
import { bunker, integer, string } from '@digitak/bunker'
const encoded12 = bunker(12, integer)
const encodedHelloWorld = bunker("Hello world!", string)
const encodedObject = bunker({
id: 42,
name: "Foo",
}, object({
id: integer,
name: string,
}))
console.log(debunker(encoded12)) // print 12
console.log(debunker(encodedHelloWorld)) // print "Hello world!"
console.log(debunker(encodedObject)) // print { id: 42, name: "Foo" }The debunker function does not need to know the schema since it is encoded along with its value.
Be cautious, a bad schema for a given value may cause unpredictable bugs!
Schema compilation
Basic example
import { bunker, number } from '@digitak/bunker'
const { encode, decode } = bunker.compile(number)
const encoded12 = encode(12)
const encoded36 = encode(36)
console.log(decode(encoded12)) // print 12
console.log(decode(encoded36)) // print 36Note that you could use debunker instead of the compiled decode function, but decode is slightly faster since it already knows the schema of the value to decode.
Naked encoding
When you don't want to encode the schema informations and only get the data you can use naked encoding:
import { bunker, number } from '@digitak/bunker'
const { encodeNaked, decodeNaked } = bunker.compile(number)
const encoded12 = encodeNaked(12)
const encoded36 = encodeNaked(36)
console.log(decodeNaked(encoded12)) // print 12
console.log(decodeNaked(encoded36)) // print 36Naked encoding slightly improves data density as well as encoding / decoding speed, but you take the risk of losing your data if you lose the schema you used.
Reading and writing files with bunker
Bunker also exports two functions to easily encode to a file / decode from a file:
async function bunkerFile(file: string, value: any, schema?: Schema): void
async function debunkerFile(file: string): unknownThese two functions scale well: you can load huge files without affecting your memory.
Basic example
import { bunkerFile, debunkerFile } from '@digitak/bunker/io'
const myObject = {
foo: 12,
bar: {
hello: "Hello",
you: "world"
}
}
bunkerFile('./myFile.bunker', myObject)
const decoded = debunkerFile('myFile.bunker')
console.log(decoded.foo) // print "12"Fetching bunker binary data from browser
Using the fetch API:
import { debunker } from '@digitak/bunker'
const response = await fetch('https://my-url/my-data.bunker')
const data = debunker(await reponse.arrayBuffer())Using axios:
import { debunker } from '@digitak/bunker'
const response = await axios.get('https://my-url/my-data.bunker', { responseType: 'arraybuffer' })
const data = debunker(response.data)Serving bunker binary data from a node server
If you serve a file, it is recommended to use streams:
import fs from 'fs'
import http from 'http'
import { bunker } from '@digitak/bunker'
http.createServer((request, response) => {
const filePath = 'myfile.bunker'
const stat = fs.statSync(filePath)
response.writeHead(200, {
'Content-Type': 'application/octet-stream',
'Content-Length': stat.size,
})
const readStream = fs.createReadStream(filePath)
readStream.pipe(response)
})
Or you can serve from any value:
import http from 'http'
import { bunker } from '@digitak/bunker'
http.createServer((request, response) => {
const encoded = bunker(12)
response.writeHead(200, {
'Content-Type': 'application/octet-stream',
'Content-Length': encoded.length,
})
response.end(encoded)
})Comparisons
Output size
Here is the comparison between JSON, Bunker (with and without schema) and MessagePack using a variety of object patterns frequently used:
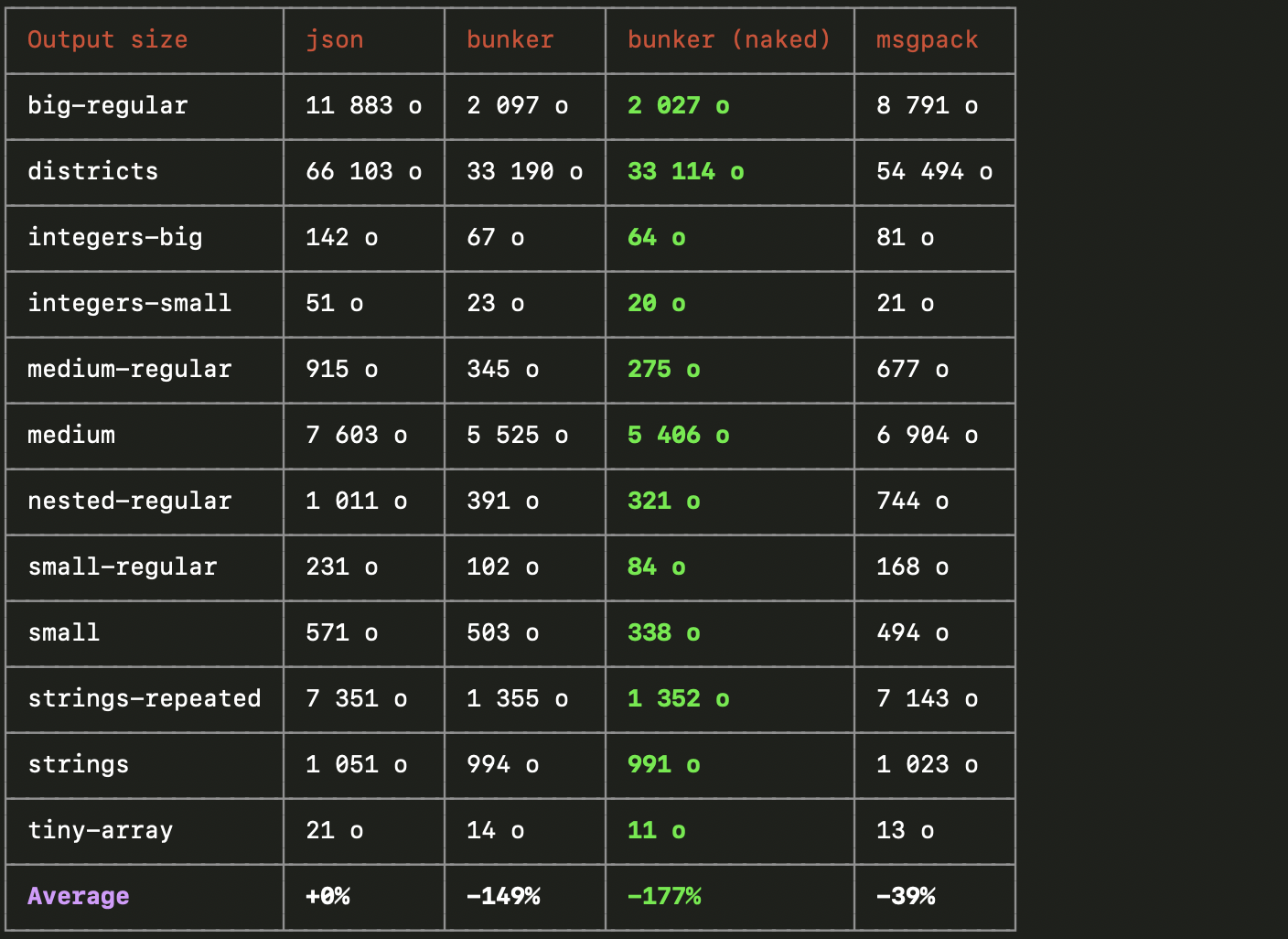
Naked bunker (ie. without the schema encoded, only data) is obviously the winner in all categories, but embedding the schema is not as costy as we may think, especially for large objects.
In average, Bunker's encoded data is:
- 2.5x smaller than JSON (2.75x smaller for naked encoding),
- 2.1x smaller than MessagePack (2.35x smaller for naked encoding).
Encoding / decoding speed
If you manually indicates the schema of your values, this Typescript implementation of the bunker binary format specification is extremely fast.
If you let Bunker guess the schema of your value though your performances will fall down.