
Package Exports
- @tokenlens/helpers
Readme
@tokenlens/helpers


![]()
![]()
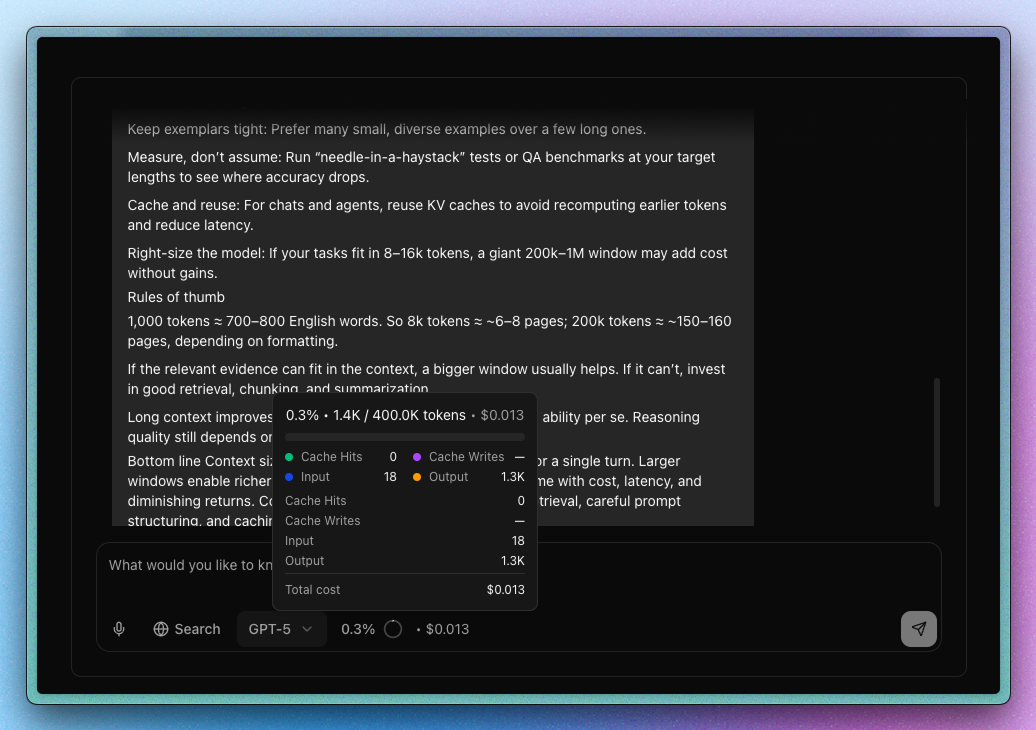
Low-level utilities for computing token costs, context health metrics, and JSON compaction. These are the building blocks used by the main tokenlens package.
Install
npm install @tokenlens/helpers
# or
pnpm add @tokenlens/helpers
# or
yarn add @tokenlens/helpersExports
Cost Calculation
computeTokenCostsForModel(args)
Calculate token costs in USD for a model with usage data.
import { computeTokenCostsForModel, type TokenCosts } from "@tokenlens/helpers";
const costs = computeTokenCostsForModel({
model: {
id: "gpt-4o-mini",
cost: {
input: 0.15, // per 1M tokens
output: 0.60, // per 1M tokens
reasoning: 0,
cacheRead: 0.075, // per 1M tokens
cacheWrite: 0.30, // per 1M tokens
}
},
usage: {
input_tokens: 1000,
output_tokens: 500,
reasoning_tokens: 0,
cacheReads: 200,
cacheWrites: 100,
}
});
console.log(costs);
// {
// inputTokenCostUSD: 0.00015,
// outputTokenCostUSD: 0.0003,
// reasoningTokenCostUSD: 0,
// cacheReadTokenCostUSD: 0.000015,
// cacheWriteTokenCostUSD: 0.00003,
// totalTokenCostUSD: 0.000495
// }Parameters:
model: Model object withcostfield containing pricing per 1M tokensusage: Usage object with token counts
Returns: TokenCosts
type TokenCosts = {
inputTokenCostUSD: number;
outputTokenCostUSD: number;
reasoningTokenCostUSD: number;
cacheReadTokenCostUSD: number;
cacheWriteTokenCostUSD: number;
totalTokenCostUSD: number;
}Context Health
getContextHealth(args)
Calculate context window health metrics including usage percentages and status.
import { getContextHealth, type ContextHealth } from "@tokenlens/helpers";
const health = getContextHealth({
model: {
id: "gpt-4o-mini",
limit: {
context: 128000,
input: 100000,
output: 16000,
}
},
usage: {
input_tokens: 90000,
output_tokens: 5000,
}
});
console.log(health);
// {
// status: "warning",
// totalTokens: 128000,
// usedTokens: 95000,
// remainingTokens: 33000,
// usedPercentage: 74.22,
// remainingPercentage: 25.78
// }Parameters:
model: Model object withlimitfield containing context/input/output limitsusage: Usage object withinput_tokensandoutput_tokens
Returns: ContextHealth
type ContextHealth = {
status: "healthy" | "warning" | "critical";
totalTokens: number;
usedTokens: number;
remainingTokens: number;
usedPercentage: number;
remainingPercentage: number;
}Status thresholds:
healthy: < 70% usedwarning: 70-90% usedcritical: > 90% used
JSON Compaction
compactJson(args)
Compact JSON objects by removing whitespace and optionally shortening keys.
import { compactJson } from "@tokenlens/helpers";
const original = {
"very_long_key_name": "value",
"another_long_key": "data"
};
const result = compactJson({
json: original,
shortenKeys: true,
minify: true
});
console.log(result);
// {
// compacted: { "vlkn": "value", "alk": "data" },
// keyMap: { "vlkn": "very_long_key_name", "alk": "another_long_key" },
// originalSize: 65,
// compactedSize: 38,
// savedBytes: 27
// }estimateTokenSavings(args)
Estimate token savings from JSON compaction.
import { estimateTokenSavings } from "@tokenlens/helpers";
const savings = estimateTokenSavings({
originalJson: { longKeyName: "value" },
compactedJson: { lkn: "value" }
});
console.log(savings);
// { estimatedTokensSaved: 3 }Usage in TokenLens
These helpers are used internally by the main tokenlens package. Most users should use the high-level Tokenlens class instead:
import { Tokenlens } from "tokenlens";
const tokenlens = new Tokenlens();
// Uses computeTokenCostsForModel internally
const costs = await tokenlens.computeCostUSD({
modelId: "openai/gpt-4o-mini",
usage: { input_tokens: 1000, output_tokens: 500 }
});
// Uses getContextHealth internally
const health = await tokenlens.getContextHealth({
modelId: "openai/gpt-4o-mini",
usage: { input_tokens: 90000, output_tokens: 5000 }
});Direct Usage
Use these helpers directly when you:
- Have model metadata already available
- Want to avoid network calls
- Need fine-grained control over the calculations
- Are building custom tooling on top of TokenLens
import {
computeTokenCostsForModel,
getContextHealth
} from "@tokenlens/helpers";
import type { SourceModel } from "@tokenlens/core";
const model: SourceModel = {
id: "custom-model",
name: "Custom Model",
cost: { input: 1, output: 2 },
limit: { context: 4096, output: 2048 }
};
const usage = {
input_tokens: 1000,
output_tokens: 500,
reasoning_tokens: 0,
cacheReads: 0,
cacheWrites: 0,
};
const costs = computeTokenCostsForModel({ model, usage });
const health = getContextHealth({ model, usage });
console.log({ costs, health });License
MIT