
Package Exports
- @tokenlens/helpers
- @tokenlens/helpers/context
- @tokenlens/helpers/conversation
- @tokenlens/helpers/simple
Readme
@tokenlens/helpers


![]()
![]()
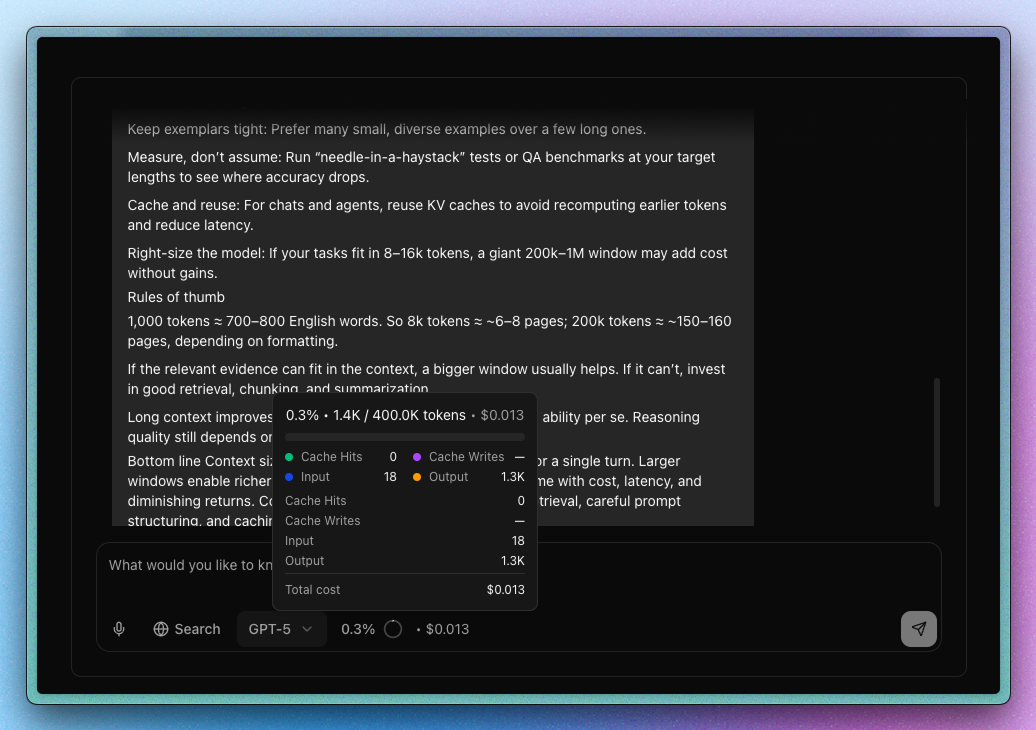
Utility helpers focused on context caps and rough cost estimation.
DI‑first: pass providers from fetchModels() (or getModels() for a static set).
Install
- npm:
npm i @tokenlens/helpers - pnpm:
pnpm add @tokenlens/helpers - yarn:
yarn add @tokenlens/helpers
Focused Exports
- Context:
getContext({ modelId, providers }) - Cost:
getTokenCosts({ modelId, usage, providers }) - Combined:
getUsage({ modelId, usage, providers, reserveOutput? }) - Types:
ContextData,TokenCosts,UsageData
Deprecated (use focused exports instead)
- Context:
getContextWindow,remainingContext,percentRemaining,fitsContext - Usage:
normalizeUsage,breakdownTokens,consumedTokens - Cost:
estimateCost - Compaction:
shouldCompact,contextHealth,tokensToCompact - Conversation:
sumUsage,estimateConversationCost,computeContextRot,nextTurnBudget - DI:
sourceFromModels,sourceFromCatalog,selectStaticModels
Usage
import { fetchModels } from 'tokenlens';
import { getContext, getTokenCosts, getUsage } from '@tokenlens/helpers';
const openai = await fetchModels('openai');
const modelId = 'openai/gpt-4o-mini';
const usage = { prompt_tokens: 1000, completion_tokens: 500 };
const { maxInput, maxOutput, maxTotal } = getContext(modelId, openai);
const {
inputUSD,
outputUSD,
reasoningUSD,
cacheReadUSD,
cacheWriteUSD,
totalUSD,
} = getTokenCosts(modelId, usage, openai);
const summary = getUsage(modelId, usage, openai);Notes
- IDs can be
provider/model,provider:id, or providerlessmodel. - Version dots normalize to dashes in the model segment.
- Cost outputs are estimates based on models.dev pricing fields. For authoritative cost numbers, read pricing and usage metrics from your model provider's API responses at runtime.
Back‑compat via tokenlens
import { getContext, getTokenCosts, getUsage } from 'tokenlens';
// These wrappers inject a default providers set if not supplied.License MIT